VIGA: New AI Agent Turns 2D Images into Editable 3D Blender Scenes
A new closed-loop agent reconstructs images into editable graphics programs, improving 3D benchmarks by over 100%.
A New Era for Inverse Graphics: VIGA Reconstructs 3D Scenes from Images
Researchers from UC Berkeley and partner institutions have introduced VIGA (Vision-as-Inverse-Graphics Agent), a novel AI system capable of transforming a single 2D image into a fully editable 3D graphics program. Submitted to arXiv on January 16, 2026, this paper tackles a long-standing challenge in computer vision: bridging the gap between flat visual data and structured, physically grounded 3D environments.
For developers and founders in the 3D space, VIGA represents a shift from black-box 3D generation to code-based scene reconstruction, enabling high-precision editing and physics simulation in engines like Blender. As recent advancements in physical AI models demonstrate, the industry is moving toward AI systems that understand not just visual appearance but also physical constraints and simulations.
The Problem with Current VLMs
While Vision Language Models (VLMs) have demonstrated impressive capabilities in describing images, they often struggle with "inverse graphics" the process of deconstructing an image into the code required to render it. Traditional VLMs lack fine-grained spatial reasoning and physical grounding. When asked to generate a 3D scene from an image in a "one-shot" attempt, they frequently hallucinate geometry or fail to respect physical constraints.
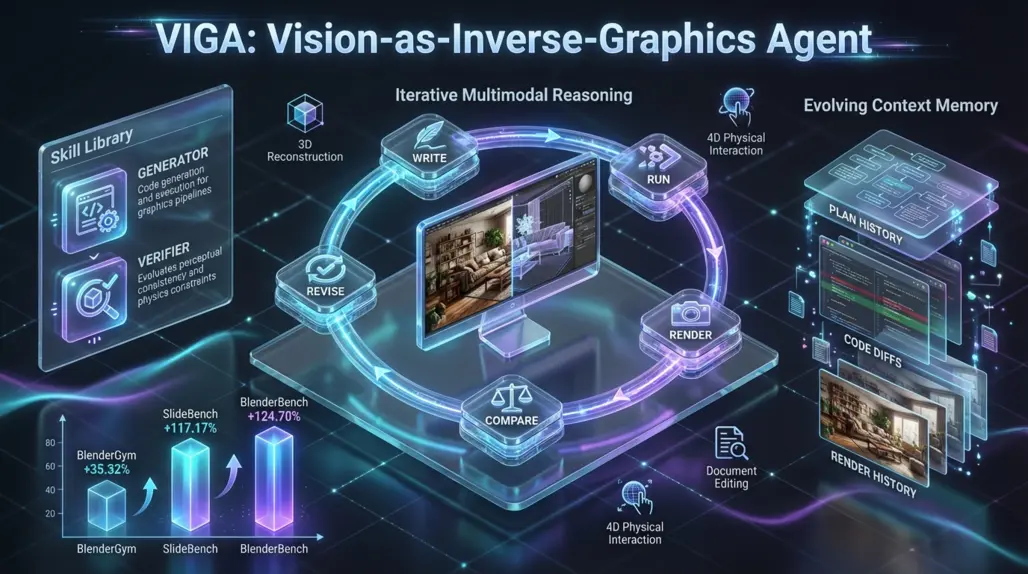
How VIGA Works: The "Write-Run-Render-Revise" Loop
VIGA moves beyond simple generation by adopting an agentic workflow that mimics how a human developer debugs code. Instead of guessing the 3D structure in a single pass, VIGA employs a closed-loop reasoning process.
The Core Cycle
- Code Generation: The agent starts with an empty world and writes code (e.g., Python scripts for Blender) to attempt to recreate the scene.
- Execution & Rendering: It executes the code to render an image of the current 3D state.
- Visual Comparison: The agent compares its rendered output against the original target image.
- Iterative Revision: Based on the visual difference, VIGA revises the code to correct errors in geometry, placement, or lighting.
This "write-run-render-compare-revise" feedback loop allows the agent to self-correct, ensuring the final output is not just visually similar but structurally accurate. This approach aligns with how autonomous agents are already redefining software engineering in enterprise environments, where AI systems can autonomously debug and fix their own code.
Under the Hood
To manage this complex process, VIGA utilizes two main components:
- Skill Library: A set of specialized functions where the agent alternates between "generator" and "verifier" roles to handle specific sub-tasks.
- Evolving Context Memory: A dynamic memory system that stores execution plans, code diffs (changes), and a history of previous renders. This prevents the agent from repeating mistakes and helps it navigate long-horizon reasoning tasks.
Performance and Benchmarks
The research team, led by Shaofeng Yin, evaluated VIGA against existing baselines and found substantial improvements across several metrics. Notably, VIGA is model-agnostic, meaning it improves the performance of various foundation models without requiring expensive fine-tuning.
- BlenderGym: Achieved a 35.32% improvement in scene reconstruction tasks.
- SlideBench: Showed a massive 117.17% improvement in 2D document editing, proving the agent's versatility beyond just 3D scenes.
- BlenderBench: The authors introduced a new, more rigorous benchmark called BlenderBench to stress-test interleaved multimodal reasoning. VIGA outperformed baselines by 124.70% on this dataset.
Implications for Builders and Developers
VIGA's approach is particularly relevant for those building tools in game development, architectural visualization, and simulation. For those exploring AI design and 3D modeling tools, VIGA offers a new paradigm that prioritizes editability and control.
- Editable Assets: Unlike neural radiance fields (NeRFs) or Gaussian Splats which are often hard to edit, VIGA generates code. This means the resulting 3D scenes are parametric and fully editable in standard software like Blender.
- Physical Simulation: Because the output is a structured graphics program, VIGA can simulate physical interactions (4D), such as how objects in the reconstructed scene would react to collision or gravity.
- Task Agnostic: The system does not rely on auxiliary modules, making it flexible enough to handle 3D reconstruction, scene editing, and even 2D layout tasks within a single framework.
By treating vision as an inverse programming problem, VIGA offers a practical path toward automating the creation of "digital twins" and interactive 3D environments from simple reference images. For developers interested in building with autonomous AI agents, VIGA showcases the power of closed-loop feedback systems in solving complex creative and technical challenges.
The Future of Inverse Graphics
VIGA represents a significant step forward in making 3D content creation more accessible and automated. As AI systems become better at understanding the relationship between visual data and the underlying code that generates it, we can expect to see more tools that bridge the gap between perception and creation.
Discover more cutting-edge AI tools and applications on Appse, your comprehensive directory for the latest innovations in artificial intelligence, from 3D modeling to autonomous agents.